闪光桐人の实习日记(2023年2月20-24日)
本文最后更新于:2023年3月23日 上午
2023年2月24日
一点SQL开发规范
自增id一般不用,不安全
逻辑删除,基础数据要用,关系数据等删了就删了
easyExcel
配置实体类
1 | |
写入
测试数据
1 | |
数据写入Excel
1 | |
效果图: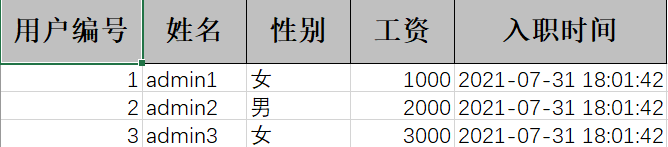
读取
读取解析:
1 | |
读取出来就是list格式的数据,再用写入的方法写入Excel再传回前端即可生成一份Excel表格文件。
下拉框
设置了下拉框后用户就只能输入下拉框的值,规范
详细
写、读功能拓展
2023年2月23日
数据库设计
ER图绘制
2023年2月22日(多线程与定时任务入门)
进程、线程、协程
是什么
- 进程:应用程序的启动实例
- 线程:从属于进程,是应用程序真正的执行者,有自己的栈空间一个进程必定会有一个主线程和若干个子线程
- 协程(go中有):一个特殊的函数
启动SpringBoot工程=>生成一个进程
用户调用接口=>controller执行=>生成一个线程
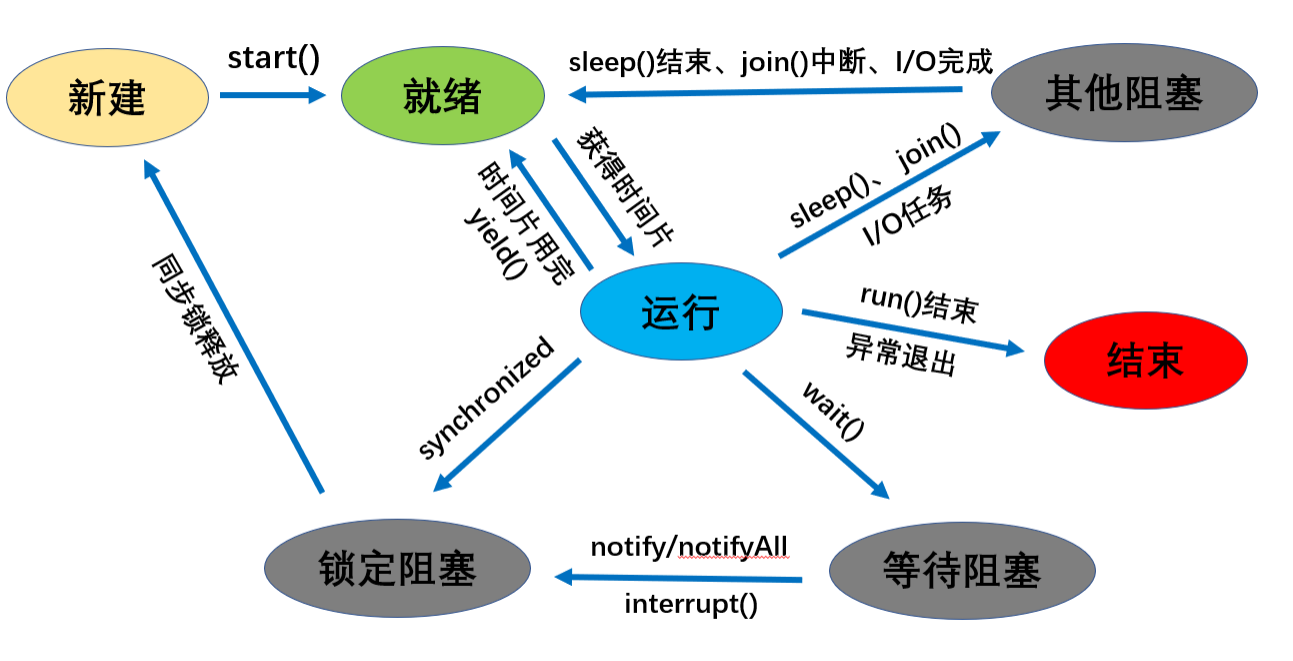
创建
- 继承Thread类
- 实现Runnable接口
线程池
配置
- 使用
@Configuration注解声明一个配置类; - 使用
@EnableAsync注解声明该配置类是一个线程池配置类; - 在配置类中用创建一个初始化线程池配置的方法,该方法的返回值是Executor(执行器接口),方法中可以对线程池设置自定义的配置参数;
- 使用
@Bean注解标识定义的配置方法,可以在@Bean里面显示指定配置名称,防止同时存在多个线程配置; - 在需要异步执行的方法上使用
@Async注解,并设置@Async的value值为对应的线程池;
1 | |
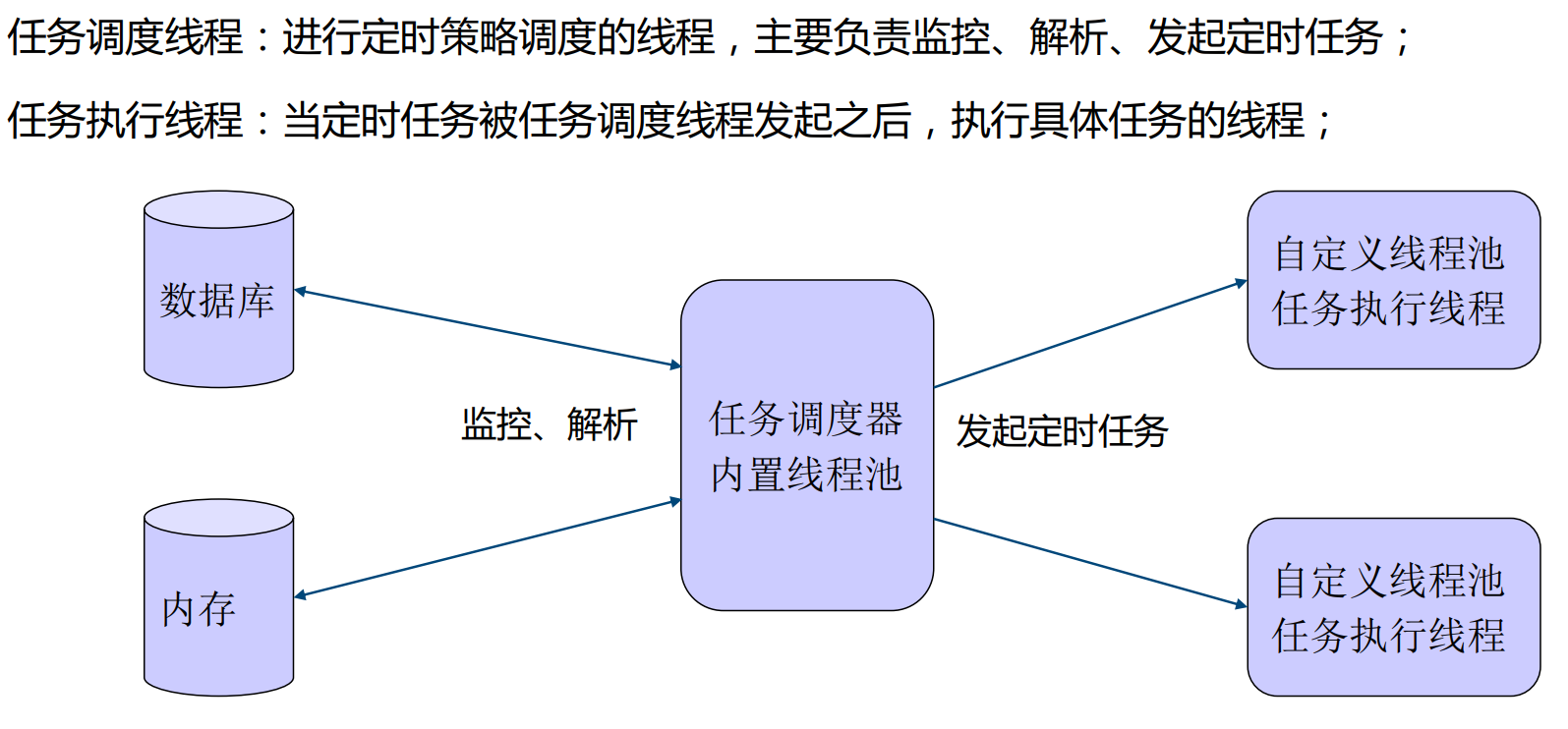
定时任务
| SpringBoot注解 | QuartZ | xxl-job | |
|---|---|---|---|
| 集成难度 | 集成方便(使用SpringBoot注解) | 存在一定门槛(引入依赖,配套相应的数据库表) | 门槛比较高(引入依赖,配套相应的数据库表,需要安装xxl-job服务端) |
| 动态变更定时策略 | 不支持动态更新(使用注解的方式定义时间策略) | 支持的动态更新(定时策略保存在数据库表) | 支持的动态更新(定时策略保存在数据库表) |
| 持久化 | 原生不支持(可以通过自定义实现) | 默认支持(可以持久化在内存或者数据库) | 默认支持(同QuartZ) |
| 任务状态管理 | 原生不支持(可以通过自定义实现) | 支持 | 支持 |
| 分布式部署 | 不支持分布式部署 | 提供数据库锁方式实现分布式,但存在Bug,可以通过改造来实现简易分布式 | 本身就是为了实现分布式定时任务 |
配置
新建一个Java类,使用@Component注解声明为Spring组件;
在该类中新建定时执行的方法,方法中执行时间点触发后执行的实际业务;
使用@Scheduled注解该方法,注解中定义执行的定时策略;
使用@Async注解该方法,指定任务执行的线程池;
在启动类上加上@EnableScheduling注解,表示自动启用定时任务
定时策略
- cron:使用cron时间表达式指定定时策略;
- fixedDelay:控制方法执行的间隔时间,是以上一次方法执行完开始算起;
- fixedRate:是按照一定的速率执行,是从上一次方法执行开始的时间算起;
- initialDelay:Spring启动后,延时指定时间执行,只执行一次;
1 | |
QuartZ
Quartz是OpenSymphony开源组织的一个开源项目,完全由Java开发,可以用来执行定时任务,类似于java.util.Timer
结构
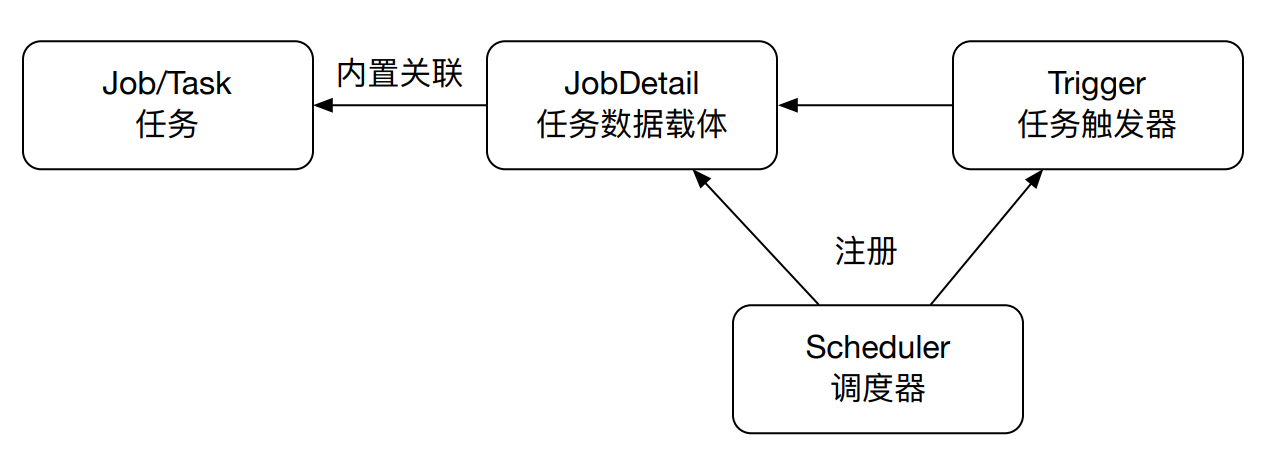
集成
- 在对应工程中引入依赖,参考time-component的pom.xml
1 | |
- 导入配套的数据库,QRTZ_开头的表
注意点:需要区分QRTZ_开头的表的大小写,默认是大写,可以将mysql设置成忽略大小写 - 新增QuartZ的配置类,使用@Configuration声明,定义具体配置方法使用,使用@Bean声明,
在方法中自定义相关配置
任务调度
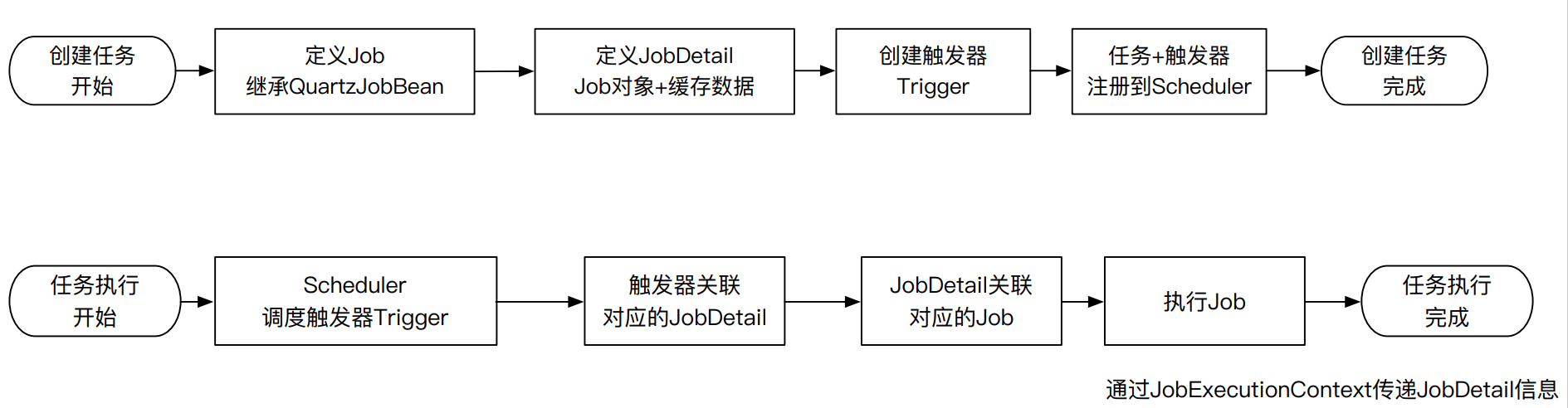
封装
- 将全部定时任务持久化统一管理,确保系统在故
障恢复后,可以还原所有定时任务? - 记录下定时任务的执行记录,方便溯源?
- 每一个任务必须要对应一个Job,同类型的不同
数据的定时任务怎么实现共用Job? - 能不能抽象出通用的Job,减少新增类型带来的
对Job的维护工作量?
封装后就可以解决这些问题
启动恢复
新建一个Java类,实现CommandLineRunner接口(在Spring初始化完成后调用),实现系统启动后,统一恢复定时任务
原理
定义一个抽象类(任务执行类),新增一个抽象方法(任务执行方法)
每一种业务类型对应一个任务执行类的继承子类(ScheduleJobEntity.beanName),并将具体的业务写到任务执行方法中
在全局唯一的QuartzJobBean的子类中,通过反射找到当前业务任务执行类,并执
行任务执行方法
XXL
2023年2月21日(禅道入门)
团队
一个人可以走得更快,一群人可以走得更远
项目管理常见问题
- 需求经常变更,开发组长忘记分配通知;经理没有跟进追踪。属于流程不规范。
- 有项测试忘了执行,但是急着上线,最终出错。属于操作不规范。
- 项目经理一直问开发完没,开发人员觉得经理烦;经理觉得开发人员效率低。属于沟通不及时不全面不深入。
项目管理工具
项目管理工具演化
阿波罗登月项目巨型计划图(100+m²)=>项目计划工具MS Project(方便制定计划,但任务跟踪难)=>基于Ticket的任务跟踪系统(任务可量化,但状态不直观)=>基于看板的可视化管理工具
禅道
优点
- 国内唯一开源工具(二开)
- 高性价比
- 功能全面,产品成熟
缺点
- 不支持按需购买
- 缺乏体系化的效能报表
支持私有化部署
项目
什么是项目
为创建独特的产品、服务和成果而进行的临时性工作
迭代
将项目拆分成为更小粒度的周期,持续交付,及时纠正方向和问题,极大减少失败风险
三种模式
Scrum
滑板=>滑板车=>自行车=>摩托车=>小汽车
瀑布
一个轮子=>底盘=>车壳=>小汽车
看板
拖拽任务
禅道使用
我的地盘
- 仪表盘
- 待办
- 日志
- 贡献
文档管理
- 项目文档库
- 产品文档库
- 自定义文档库
快速检索
- 检索标签
- 保存搜索条件
- ID快速跳转
统计报表
- 看板
- 视图
- 统计报表
2023年2月20日(Vue入门)
概念
什么是前端?
系统用于可视化传递信息的部分
前端的核心技术是什么?
超文本标记语言HTML,级联样式表CSS,脚本语言JavaScript
三个核心技术的关系是什么?
主体结构HTML,装修美化CSS,行为动作JavaScript(使静态的东西有了动态的效果);
HTML用来标记内容(重在内容组织),CSS用来修饰内容样式(重在内容美化),JavaScript用来交互(重在动作交互)。
ECMAJavaScript简介
ES6是ES2015~2021的统称
ES6中leet、const、var三者的区别?
var:函数级作用域,变量提升,值可更改
let:块级作用域,不存在变量提升,值可更改
const:块级作用域,不存在变量提升,值不可更改
变量提升:
当前区域不存在定义的时候会去往上一级找是否存在自己这个变量名的声明
例如:在当前函数内找不到a的定义,a会去上一级,也就是函数被调用的地方找有没有自己这个a的定义
1 | |
1 | |
ES6 Set数据结构和Map数据结构的区别
Set:存储无重复值的有序列表,key就是属性值
Map:键值对
ES6 Promise
Promise解决了回调地狱的问题
Vue基础
Vue的工程结构
精装:element-ui
毛坯:vue-demo
脚手架:vue-cli
地基:node.js
Vue中的MVVM
MVC:Model-View-Controller
MVP:Model-View-Presenter
MVVM:Model-View-Viewmodel
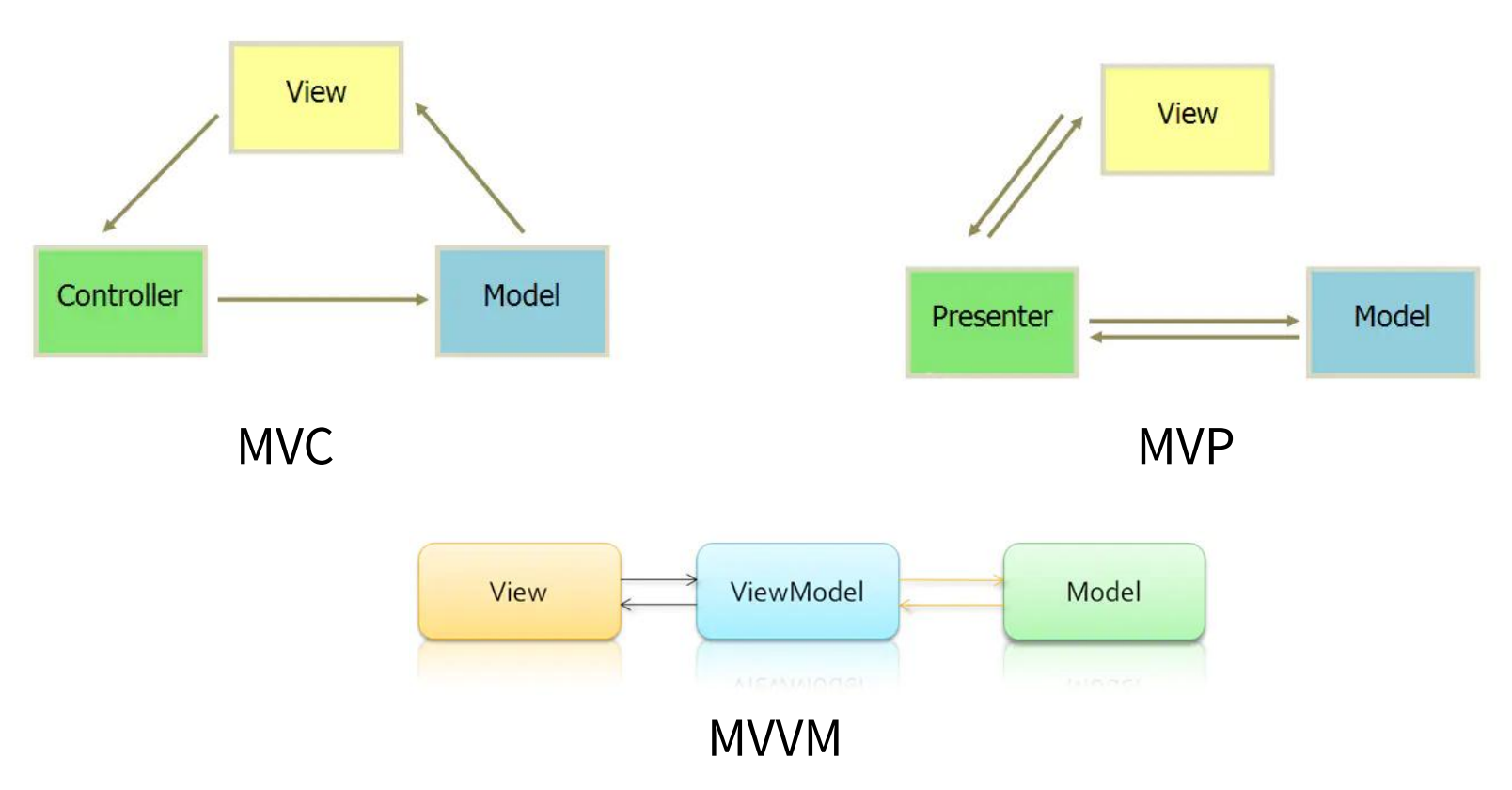
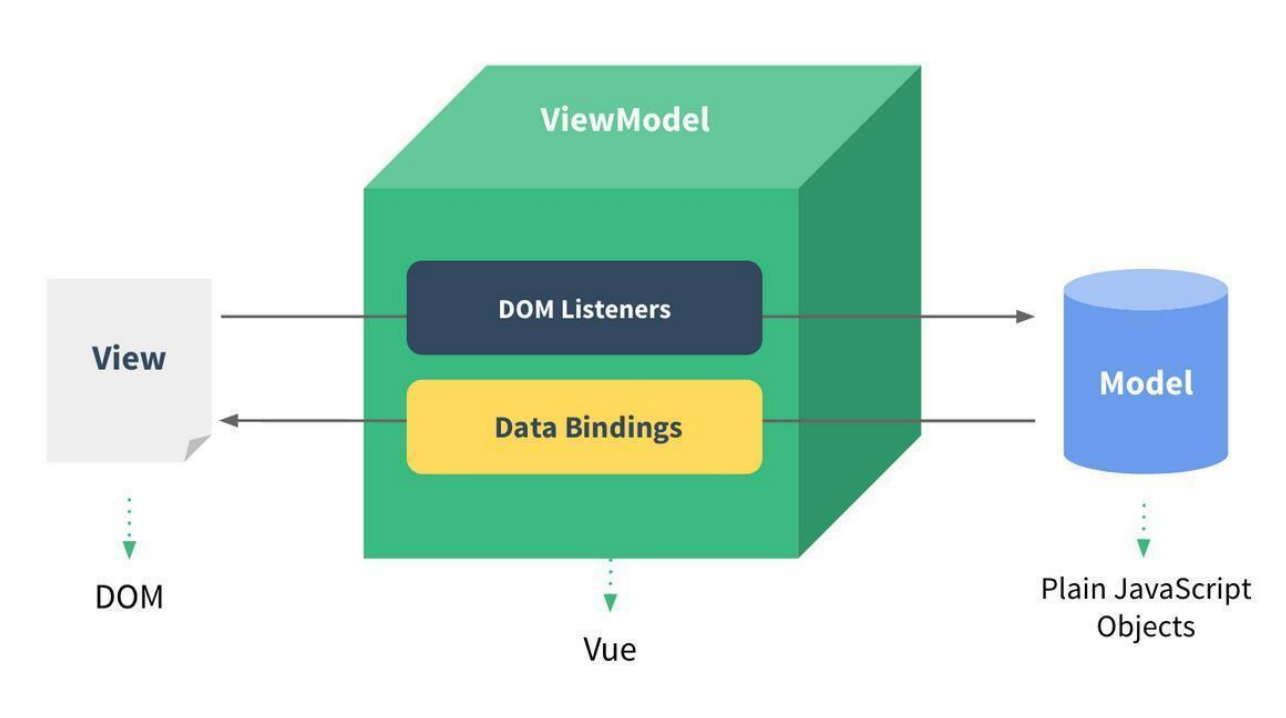
Vue的体验
搭一个出来就好了
Vue的生命周期
一张图(详情)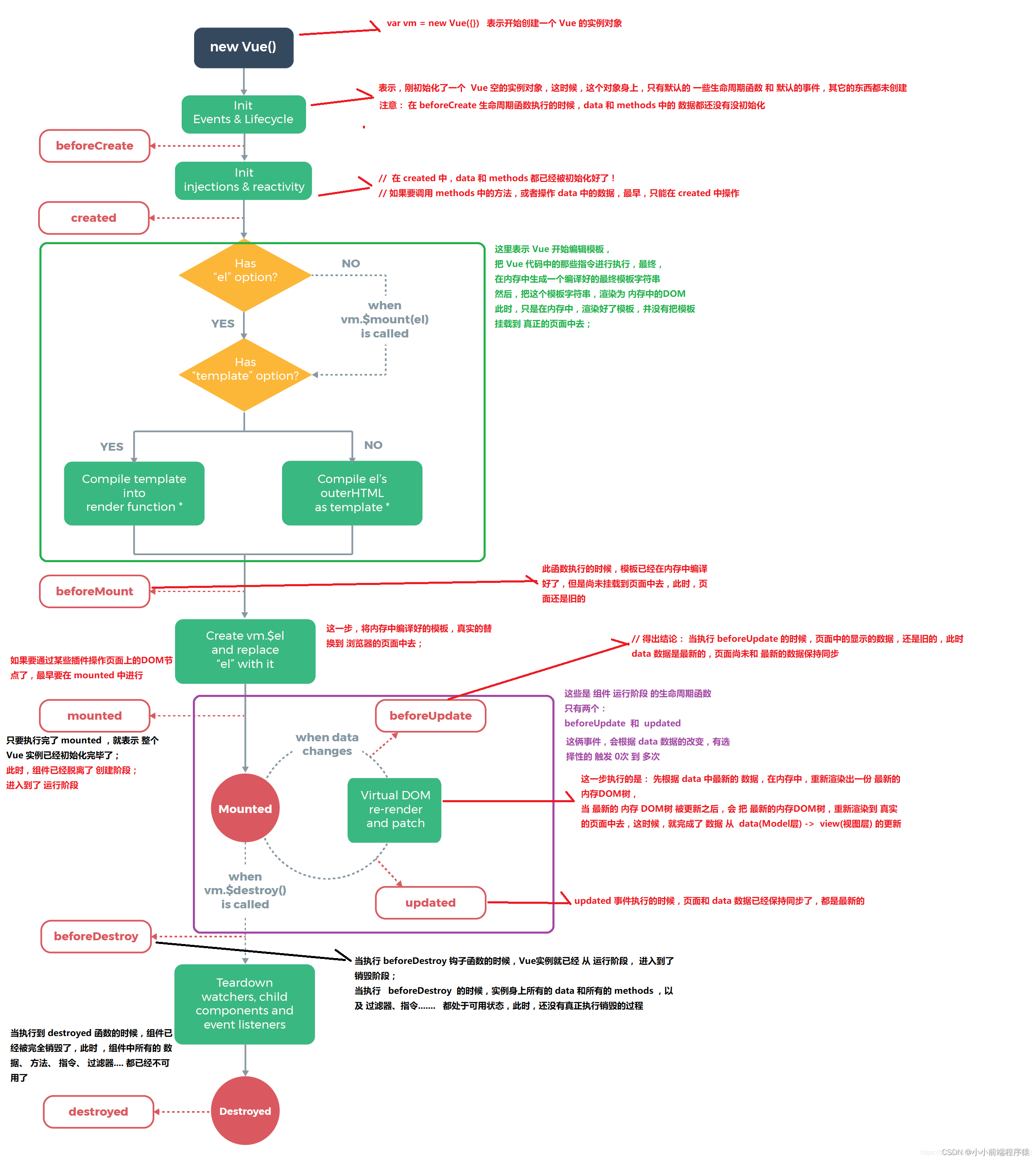
Vue指令
指令可以写在DOM元素中的小命令,以V-为前缀
v-on
v-on 是事件绑定,可以缩写为@,如果需要event就在函数里面传参;例如@click="btn($event)";
常用的修饰符也有很多:
比如
.stop用来取消冒泡事件;
.prevent阻止默认事件;
.once只执行一次;当然还有许多。
v-model
v-model 是双向绑定,一般用于文本框、单选、复选、下拉;
常用的修饰符有
.lazy - 取代 input 监听 change 事件
.number - 输入字符串转为有效的数字
.trim - 输入首尾空格过滤
v-model实际上是一个语法糖,同时用了v-bind跟v-on(数据显示跟事件绑定)
v-cloak
v-cloak页面渲染完成后消失;如果不适用的话,每次刷新页面会出现闪的一下子;就好比王者英雄出了闪现
v-once
v-once只渲染一次
v-pre
v-pre跳出渲染
v-text
v-text innerText输出
v-html(有安全隐患)
v-html innerHTML输出
v-for
v-for 和原生JS的for循环差不多
这是平常使用的一种格式
v-show
v-show 判断元素显示还是隐藏v-show="true/false"
v-if
v-if是条件判断
当然还有配套的v-else、v-else-if
与v-show的区别是,v-if条件为false时,压根不会有对应的元素在DOM中,v-show当条件为false时,仅仅是将元素的display数学设置为none而已。如果需要频繁切换,需要省去重新渲染的操作就应当用v-show
v-else
v-else-if
Vue组件
- 可独立分割
- 减少复杂度
- 可复用代码
- 随时可替换或删除
VueRouter
前后端路由的区别
后端路由:后端路由通过用户请求的URL分发到具体的处理程序,浏览器每次跳转不同的URL,都会重新访问服务器。服务器收到请求后,将数据和模板组合,返回HTML界面或模板,由前端JS请求数据,使用前端数据和模板组合生成最终的HTML界面。
前端路由:前端路由就是把不同路由对应不同的内容或页面的任务交给前端。对于单页面应用(SPA)来说,主要通过URL中的hash(#号)来实现不同页面间的切换。通过改变URL,在不重新请求页面的情况下,更新页面视图。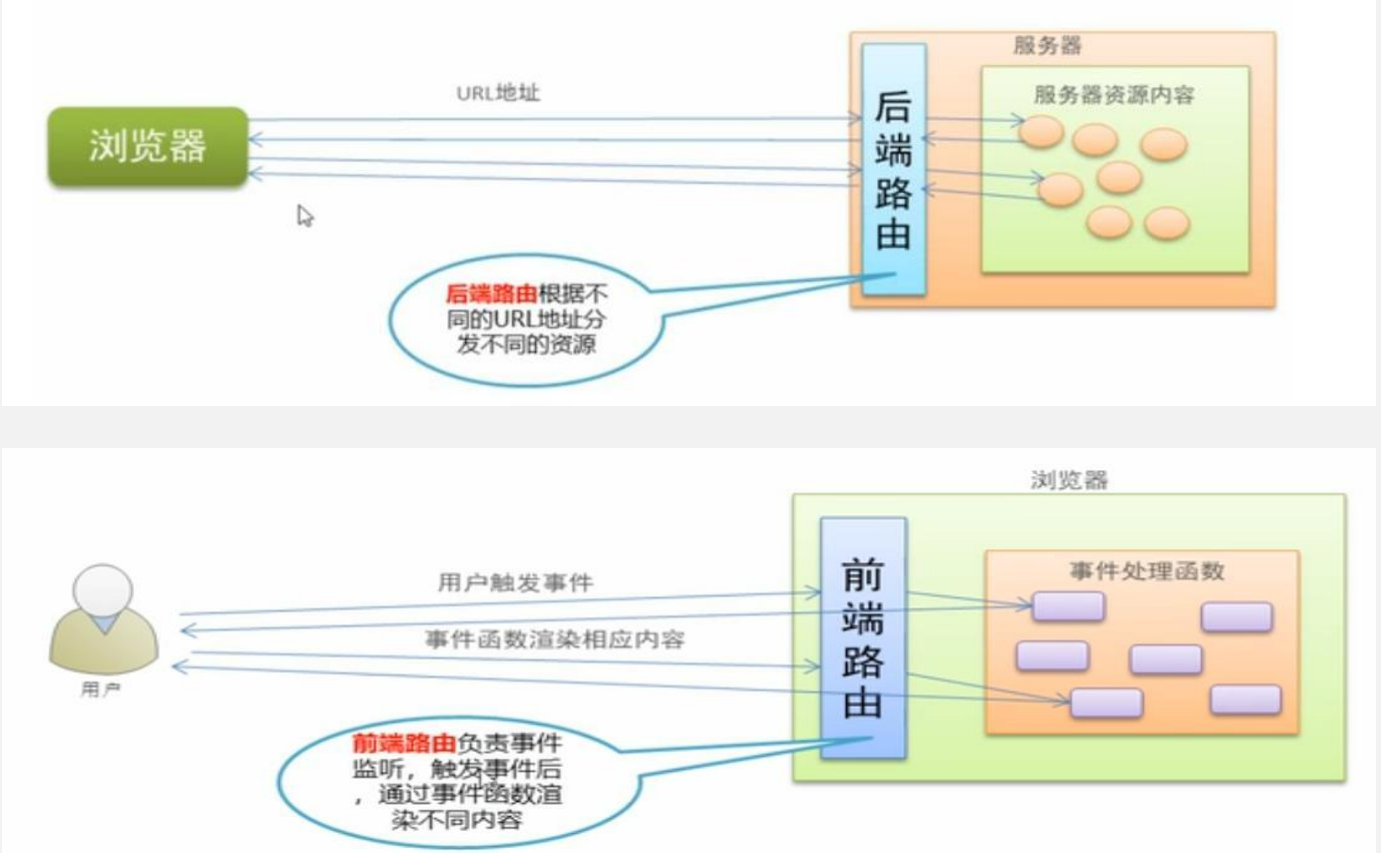
工作原理
Hash值
利用URL中的hash(“#”),可通过window.location.hash属性读取
history模式
History interface是浏览器历史记录栈提供的接口,通过back(),forward(),go()等方法,可以读取记录栈信息进行各种跳转操作
两种模式比较
更新视图但不操心请求页面是前端路由原理的核心之一
pushState设置的新URL可以是与当前URL同源的任意URL
而hash只可修改#后面的部分,故只可设置与当前同文档的URL
route跟router的区别
route、routes、router是什么?
route:表示一条路由,单数形式
routes:表示一组路由,route的集合,是一个数组
router:表示一个机制,充当管理路由的管理者角色
路由属性
路由对象(route object)表示当前激活的路由的状态信息,包含了当前URL解析得到的信息,还有URL匹配到的路由记录。this.$router表示全局路由器对象,可调用其push()、go()等方法进行路由跳转。this.$route表示当前正在用于跳转的路由对象,可以访问name、path、query、params等属性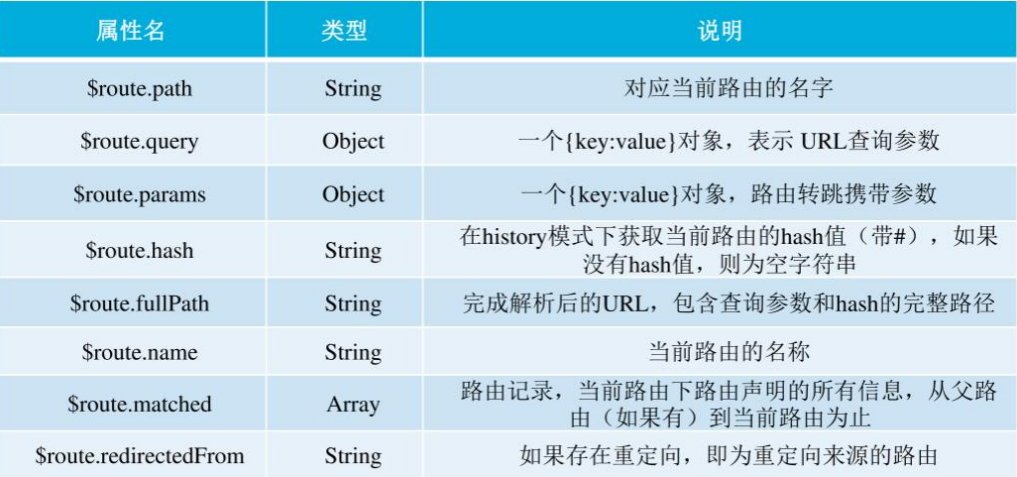
导航守卫
概念:主要用来通过跳转或取消的方式守卫导航
应用场景:项目中的登陆验证,权限控制等
全局守卫
路由实例上直接操作的钩子函数:所有路由配置的组件都会触发,只要触发路由就会触发这些钩子函数
路由守卫
指在组件内执行的钩子函数,类似于组件内的生命周期,相当于为配置路由的组件添加的生命周期钩子函数
组件守卫
是指在单个路由配置的时候也可以设置的钩子函数
回调参数
to:目标路由对象
from:即将要离开的路由对象
next:回调函数;但凡涉及到有next参数的钩子必须调用next()才能继续往下执行下一个钩子。如果要中断当前的导航要调用next(false)、next('/') 或者 next({ path:'/' }) 跳转到一不同的地址
钩子函数执行顺序: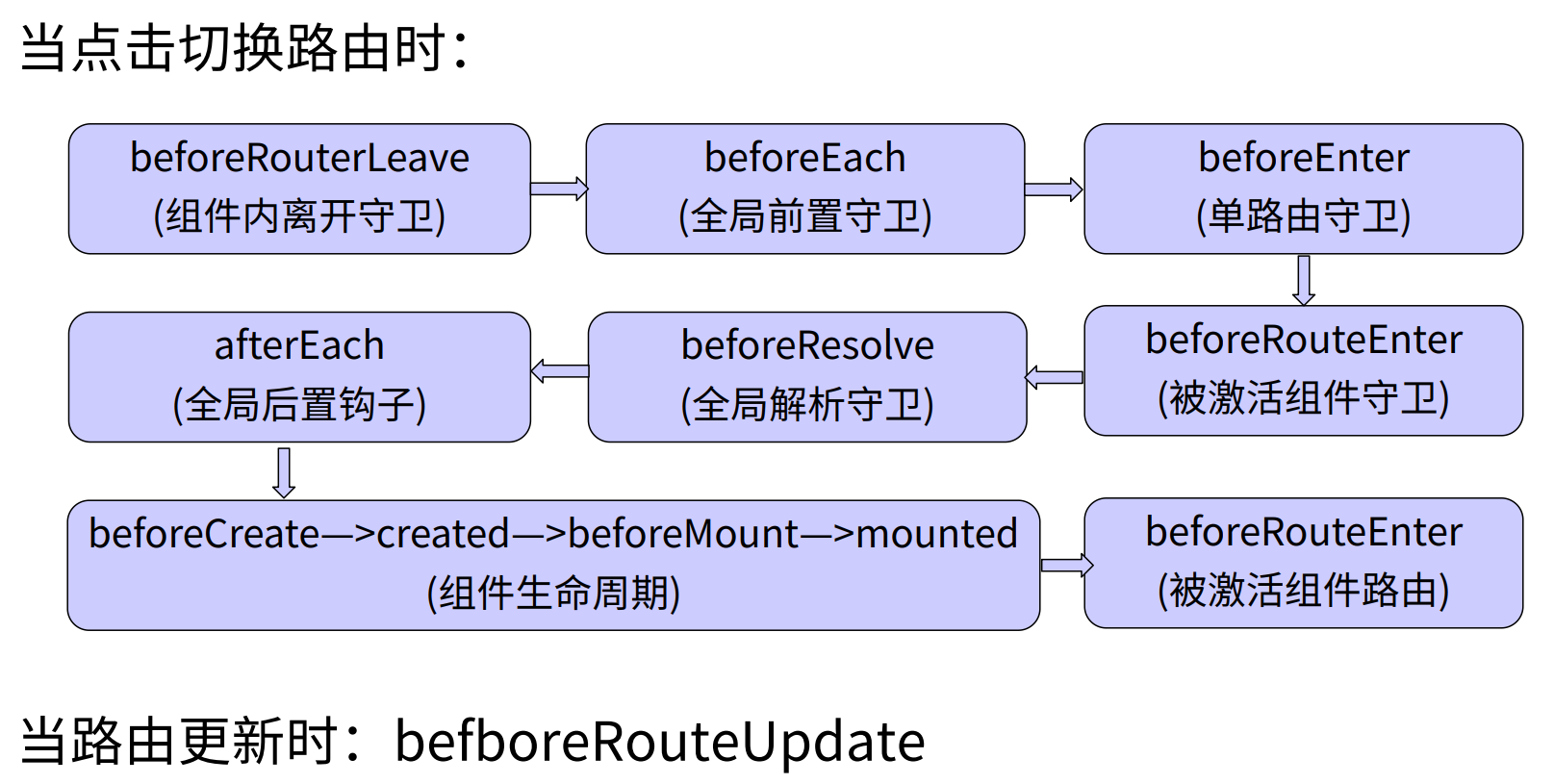
举例
Vuex
概述
是一个专为vue.js应用程序开发的状态管理模式。它能够集中管理组件间的共享数据,可以解决不同组件间共享数据的问题。
5种基本对象
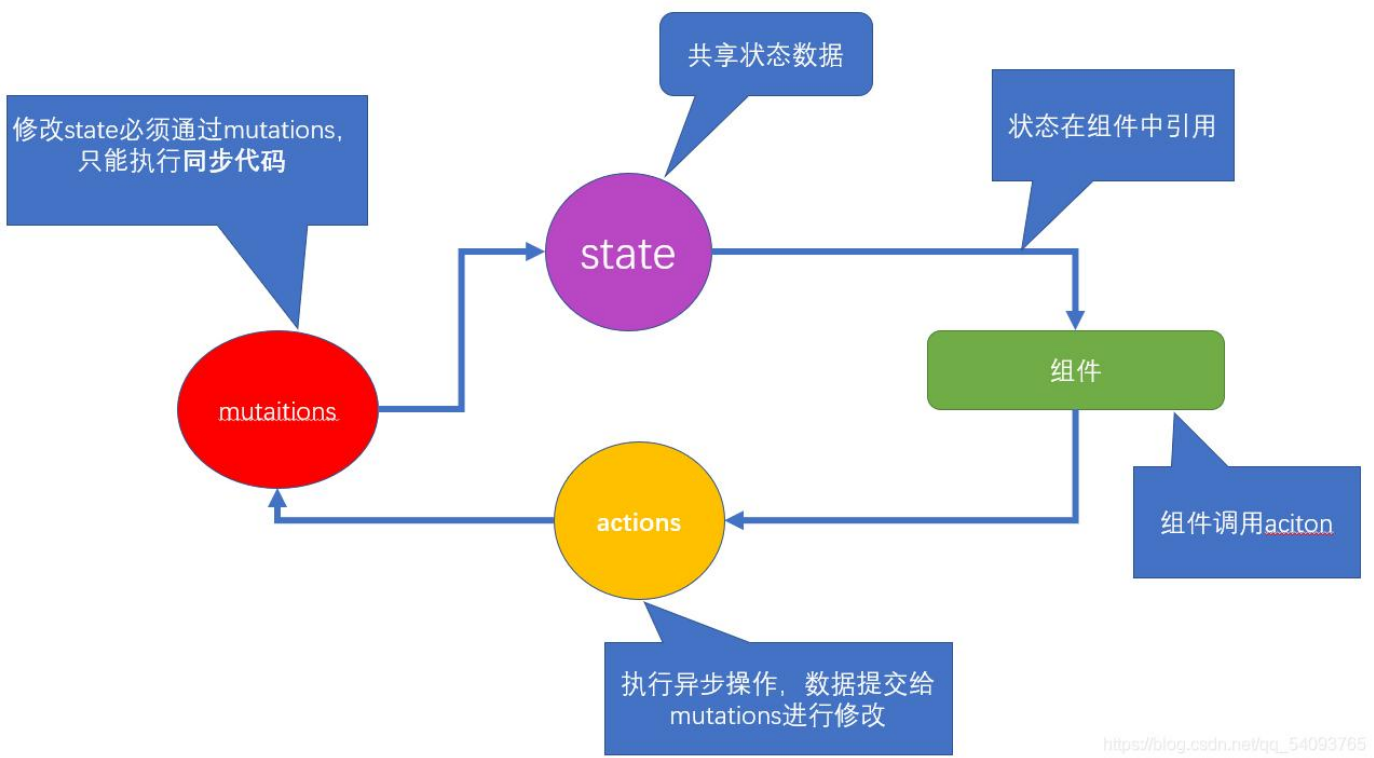
state:放置所有公共状态的属性
getters:对数据获取之前的再次编译,可以理解为state的计算属性
mutations:state数据的修改只能通过mutations,并且mutations必须是同步更新,操作state数据的方法的集合
actions:state是存放数据的,mutations是同步更新数据,actions则是负责进行异步操作
module:vuex模块化,将store分割成模块进行管理
基本使用
创建store.js文件:
下载vuex:使用命令行npm install vuex –save
引入vuex:在store.js中引入vuex
定义所需store数据
在main.js中引入store,指向store根实例
在组件中使用
辅助函数
当一个组件需要获取多个状态时候,将这些状态都声明为计算属性会有些重复和冗余。为了解决这个问题,我们可以使用mapState 辅助函数帮助我们生成计算属性
mapState,mapGetters,mapMutations,mapActions
帮助我们把store中的属性数据映射到组件的计算属性中, 它属
于一种方便用法
后两节老师讲得好快啊听了就没法记笔记,记笔记就听不懂了!