本文最后更新于 2024年11月7日 下午
一、Hadoop概述:了解关于大数据的基本常识(简答、选择、判断)
1.什么是hadoop?特点/优点?
(1)什么是Hadoop
Hadoop作为新一代的架构和技术,因为有利于并行分布处理 “大数据”而备受重视。
Apache Hadoop 是一个用java语言实现的软件框架,在由大量计算机组成的集群中运行海量数据的分布式计算,它可以让应用程序支持上千个节点和PB级别的数据。 Hadoop是项目的总称,主要是由分布式存储(HDFS)、分布式计算(MapReduce)等组成。
(2)特点/优点:
可扩展:不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。
经济:框架可以运行在任何普通的PC上。
可靠:分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性。
高效:分布式文件系统的高效数据交互实现以及MapReduce结合Local Data处理的模式,为高效处理海量的信息作了基础准备。
2.Hadoop常见的部署方式
Hadoop集群的部署方式方式分为三种,分别是独立模式(Standalone mode)、伪分布式模式(Pseudo-Distributed mode)、完全分布式模式(Cluster mode),具体介绍如下。
(1)独立模式
又称为单机模式,在该模式下,无需运行任何守护进程,所有的程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常方便,所以一般情况下,该模式在学习或者开发阶段调试使用。
(2)伪分布式模式
Hadoop程序的守护进程运行在一台节点上。
通常使用伪分布式模式用来调试Hadoop分布式程序的代码,以及程序执行是否正确,伪分布式模式是完全分布式模式的一个特例。
(3)完全分布式模式
Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节点担任不同的角色。
在实际工作应用开发中,通常使用该模式构建企业级Hadoop系统。
在Hadoop环境中,所有服务器节点仅划分为两种角色,分别是master(主节点,1个)和slave(从节点,多个)。因此,伪分布模式是集群模式的特例,只是将主节点和从节点合二为一罢了。
3.参数配置
编辑hadoop-env.sh
1
| export JAVA_HOME=/usr/local/jdk/
|
gedit core-site.xml:
1
2
3
4
5
6
7
| <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop0:9000/</value>
<description>NameNode URI</description>
</property>
</configuration>
|
gedit hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| <configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop0:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop0:50090</value>
</property>
</configuration>
|
gedit yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| <configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop0:8025</value></property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop0:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop0:8050</value>
</property>
</configuration>
|
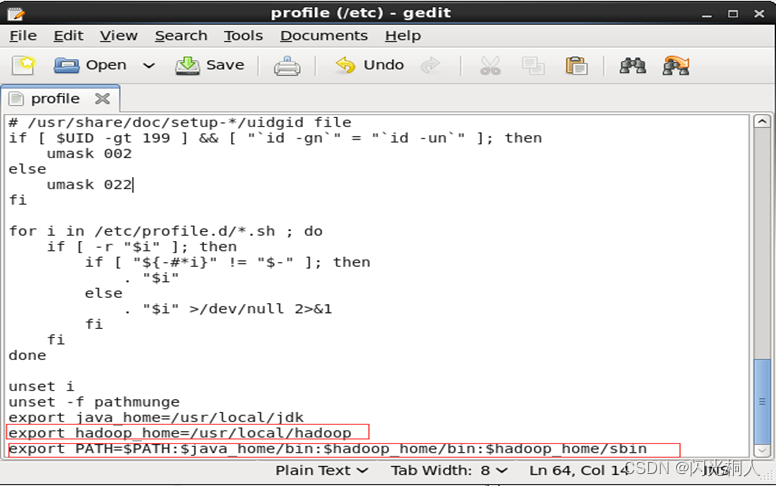
gedit /etc/profile
1
2
3
| export JAVA_HOME=/usr/local/jdk
export HADOOP_HOME=/usr/local/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
|
格式化hadoop
启动hadoop
二、Linux的常用命令及作用(选择、判断)
1.Linux命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| ls :列出目录
cd :切换目录
pwd :显示目前的目录
mkdir :创建一个新的目录
-m :配置文件的权限喔!直接配置,不需要看默认权限 (umask) 的限制
-p :帮助你直接将所需要的目录(包含上一级目录)递归创建起来!
rmdir :删除一个空的目录
-p :连同上一级『空的』目录也一起删除
如果删除的目录不为空,则不能删除
cp : 复制文件或目录
rm : 移除文件或目录
-f :就是 force 的意思,忽略不存在的文件,不会出现警告信息;
-i :互动模式,在删除前会询问使用者是否动作
-r :递归删除啊!非常危险的选项!!(传说中的删库跑路)
mv : 移动文件与目录,或修改文件与目录的名称
-f :force 强制的意思,如果目标文件已经存在,不会询问而直接覆盖;
-i :若目标文件 (destination) 已经存在时,就会询问是否覆盖!
-u :若目标文件已经存在,且 source 比较新,才会升级 (update)
cat :查看文件
vi :编辑文件
ip a :查看当前ip
service network restart :重启网络
vi /ect/profile :编辑环境变量
source /etc/profile :让环境变量生效
ifconfig :查看网卡的信息
|
2.SSH的知识点
SSH 为 Secure Shell 的缩写,由 IETF 的网络小组(Network Working Group)所制定;SSH 为建立在应用层基础上的安全协议
SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH最初是UNIX系统上的一个程序,后来又迅速扩展到其他操作平台。SSH在正确使用时可弥补网络中的漏洞。
SSH客户端适用于多种平台。几乎所有UNIX平台—包括HP-UX、Linux、AIX、Solaris、Digital UNIX、Irix,以及其他平台,都可运行SSH。
三、HDFS的概述、结构、原理!!!(简答、选择、判断)
1.hadoop fs的常用命令
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| hadoop fs -ls hdfs_path //查看HDFS目录下的文件和子目录
hadoop fs –lsr //循环列出目录、子目录及文件信息
hadoop fs -mkdir hdfs_path //在HDFS上创建文件夹
hadoop fs -rm hdfs_path //删除HDFS上的文件
hadoop fs -rmr hdfs_path //删除HDFS上的文件夹
hadoop fs -put local_file hdfs_path //将本地文件copy到HDFS上
hadoop fs -get hdfs_file local_path //复制HDFS文件到本地
hadoop fs -cat hdfs_file //查看HDFS上某文件的内容
hadoop fs -cat hdfs_path //将路径指定的文件内容输出到 stdout
hadoop fs -tail hdfs_path //将文件尾部1k字节的内容输出到 stdout
hadoop fs -stat hdfs_path //返回指定路径的统计信息
hadoop fs -du hdfs_path //返回目录中所有文件的大小,或者只指定一个文件时,显示该文件的大小
hadoop job –kill [job-id] //将正在运行的hadoop作业kill掉
端口是50070和9000
|
2.hdfs的定义,特点,数据块大小
(1)定义:
数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 。
Hadoop提供了称为HDFS分布式系统,即Hadoop Distributed Filesystem。
(2)特性:
- 是一种允许文件通过网络在多台主机上分享的文件系统,可让多机器上的多用户分享文件和存储空间。
- 具备通透性。让实际上是通过网络来访问文件的动作,由程序与用户看来,就像是访问本地的磁盘一般。
- 具备良好的容错机制保证可靠性。即使系统中有某些节点脱机,整体来说系统仍然可以持续运作而不会有数据损失。
- 适用于一次写入多次查询的情况。
(3)数据块大小:
HDFS默认Block大小是64MB(Hadoop2是128M)
3.namenode的定义和作用
(1)定义:
NameNode(元数据节点,主节点)是整个文件系统的管理节点。
(2)作用:
- 它维护着整个文件系统的文件目录树、文件/目录的元信息和每个文件对应的数据块列表。
- 接收用户的操作请求。
4.datanode的定义和作用
(1)定义:
是文件系统的数据结点。
(2)作用:
- 客户端或者元数据信息可以向数据节点请求写入或者读出数据块。
- 其周期性的向元数据节点汇报其存储的数据块、元数据信息。
- 提供真实文件数据的存储服务。
5.secondary namenode的定义和作用
(1)定义:
是namenode的冷备份。
(2)作用:
- 周期性将元数据节点的命名空间镜像文件和修改日志合并,以防日志文件过大。
- 合并过后的命名空间镜像文件也在从元数据节点保存了一份,以防元数据节点失败的时候,可以恢复。
四、MapReduce概述、结构、原理(简答、选择、判断)
1.yarn组件有什么内容,resource manager、nodemanager、application master作用
(1)yarn组件内容
yarn 主要由ResourceManager、NodeManager、ApplicationMaster、Container、Scheduler 等几个组件构成。
(2)作用
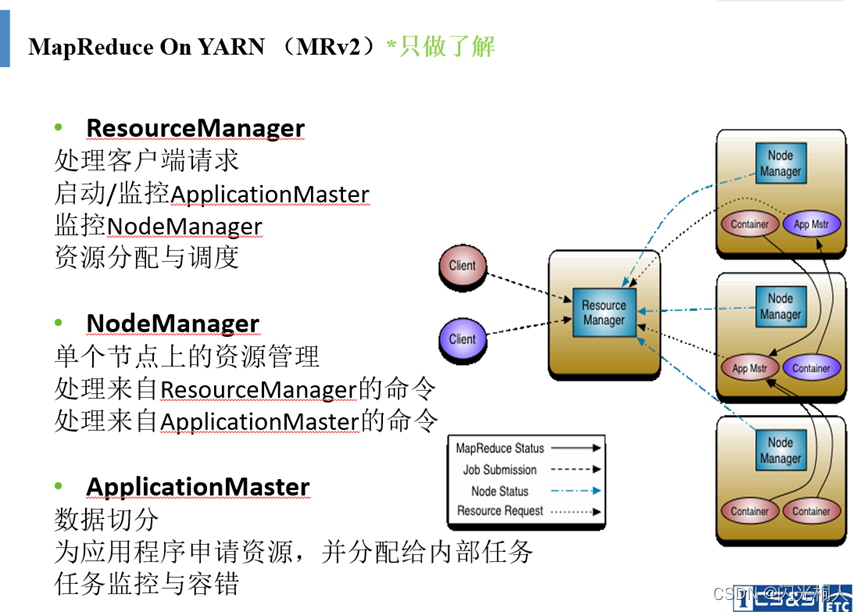
2.MapReduce编程模型,概述,详细的介绍
MapReduce是一个编程模型,一个处理和生成超大数据集的算法模型的相关实现。简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。
MapReduce成功的最大因素是它简单的编程模型。程序员只要按照这个框架的要求,设计map和reduce函数,剩下的工作,如分布式存储、节点调度、负载均衡、节点通讯、容错处理和故障恢复都由mapreduce的实现框架(比如hadoop)自动完成,设计的程序有很高的扩展性。
五、MapReduce排序、分区、自定义类型(编程、简答、选择)
1.MapReduce排序

2.Combiner、Partitioner(分区)
Combiner和Partitioner是用来优化MapReduce的。可以提高MapReduce的运行效率。
(1)Combiner
Combiner的作用是使map输出更紧凑,写到本地磁盘和传给reducer的数据更少。
(2)Partitioner(分区)
Partitioner是MapReduce中非常重要的组件。
Partitioner的作用是针对Mapper阶段的中间数据进行切分,然后将相同分片的数据交给同一个reduce处理。
Partitioner过程其实就是Mapper阶段shuffle过程中关键的一部分。
Partitioner是MyPartitioner的基类,如果需要定制partitioner也需要继承该类。
3.自定义数据类型

六、WordCount原理(简答、选择)
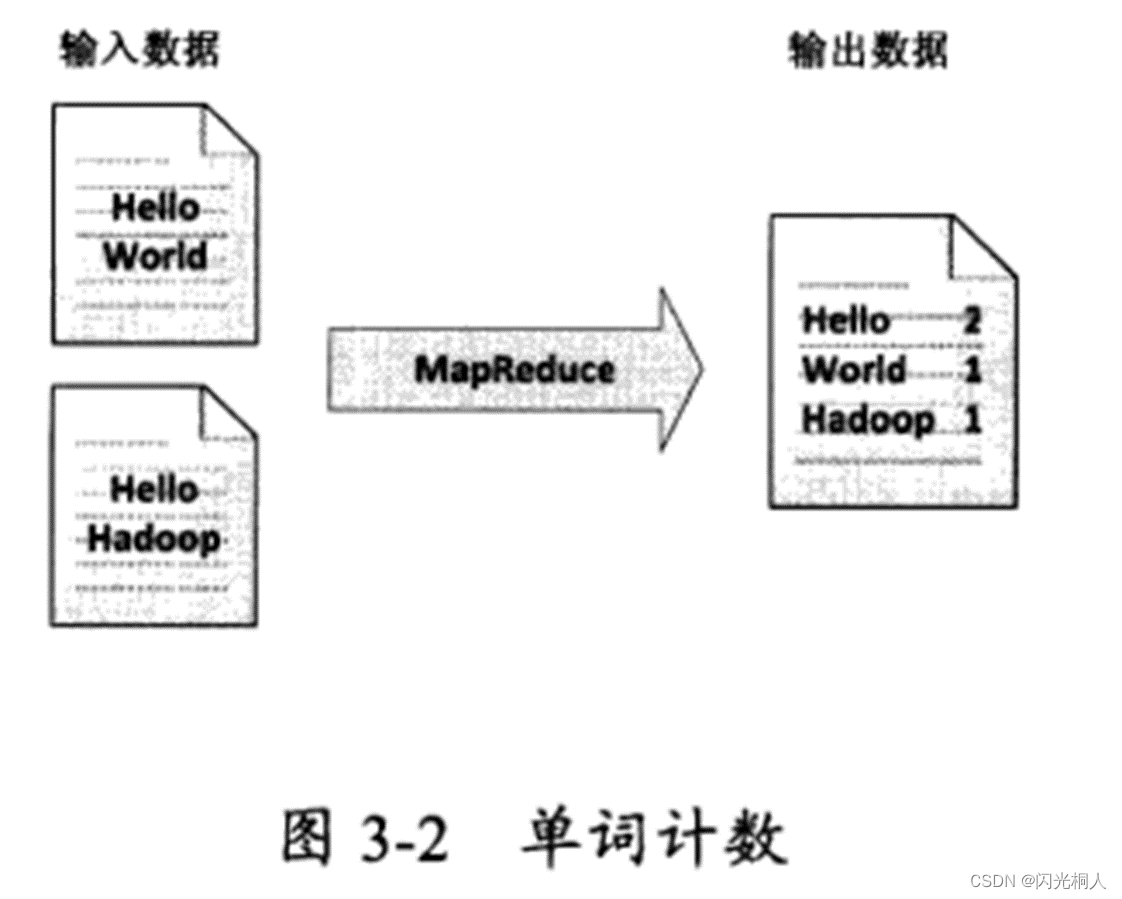
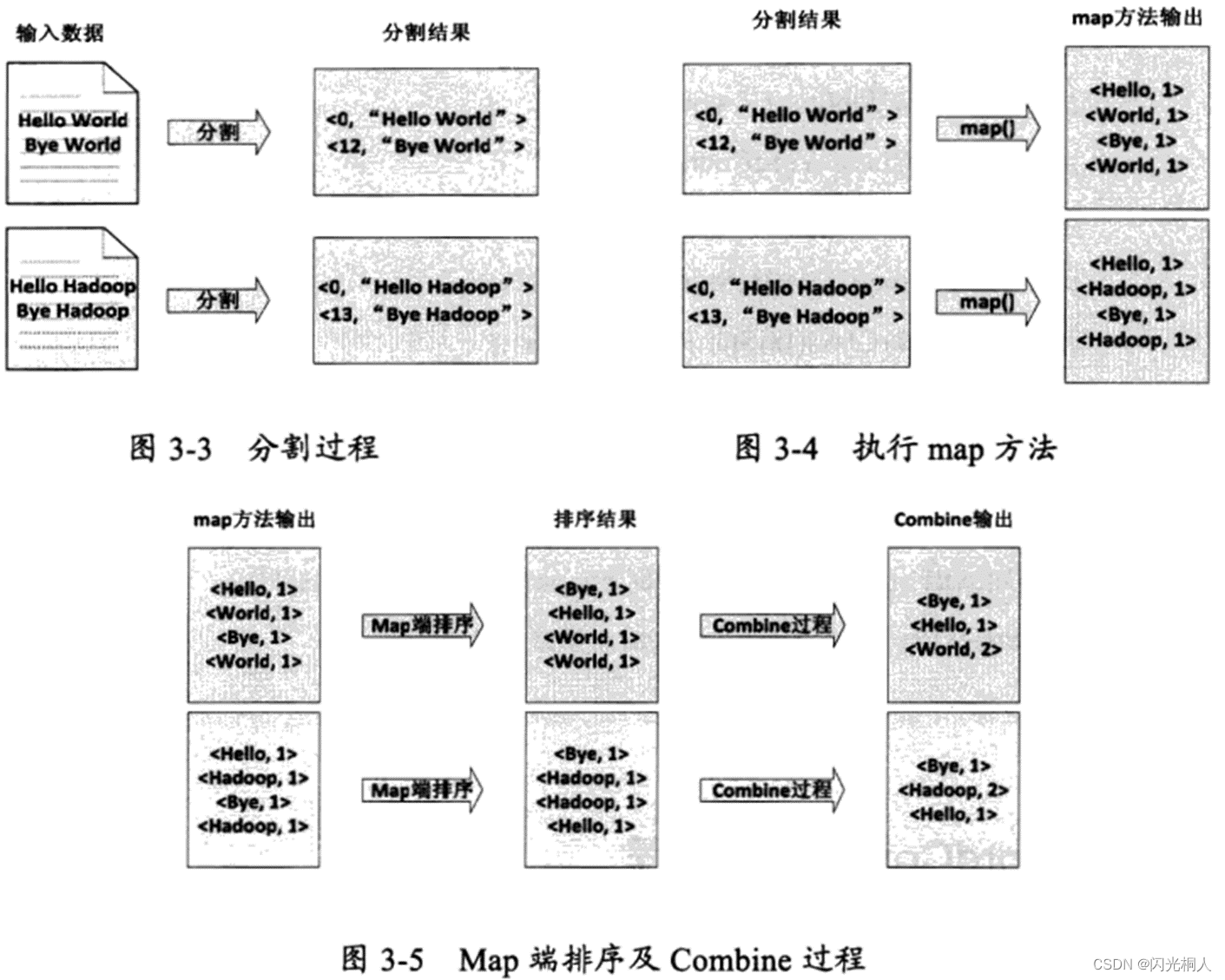
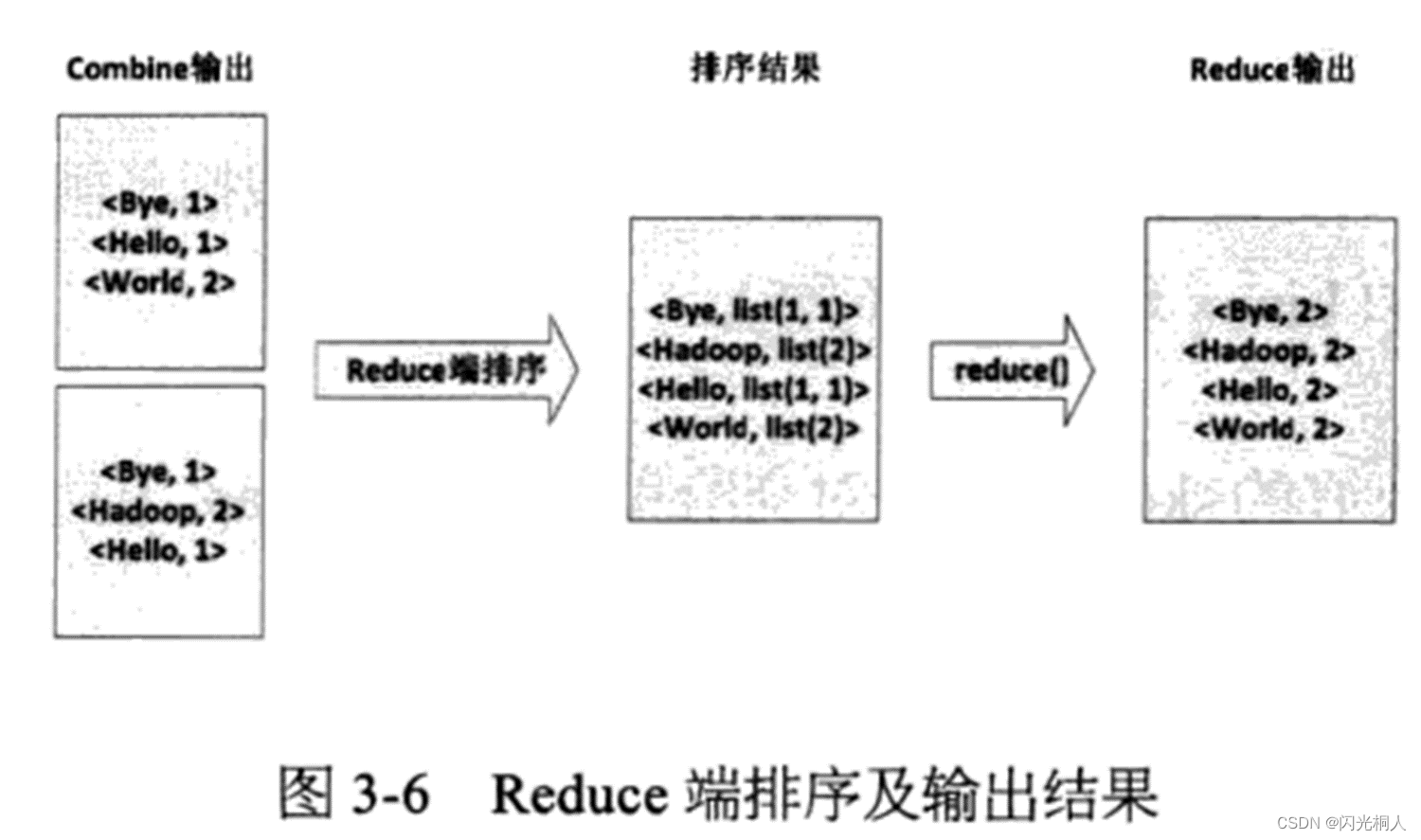
七、编程题
map reduce wordcount
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| public class WordCountDemo {
private static final String INPUT="hdfs://192.168.226.129:9000/input";
private static final String OUTPUT="hdfs://192.168.226.129:9000/output";
private static Connection connection;
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
String string = value.toString();
String[] strings = string.split(" ");
for(String str:strings) {
context.write(new Text(str), new LongWritable(1));
}
}
}
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> value,
Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long count=0;
for(LongWritable v:value) {
count+=v.get();
}
context.write(key, new LongWritable(count));
Table table=connection.getTable(TableName.valueOf("wordcount"));
Put put=new Put(Bytes.toBytes("xyj"));
put.addColumn(Bytes.toBytes("result"), Bytes.toBytes(key.toString()), Bytes.toBytes(count+""));
table.put(put);
if(table!=null)table.close();
}
}
public static void main(String[] args) throws ClassNotFoundException, IOException, InterruptedException, URISyntaxException {
Configuration confHbase=HBaseConfiguration.create();
confHbase.set("hbaes.rootdir", "hdfs://192.168.226.129:9000/hbase");
confHbase.set("hbase.zookeeper.quorum", "192.168.226.129");
connection=ConnectionFactory.createConnection(confHbase);
Admin admin=connection.getAdmin();
if(!admin.tableExists(TableName.valueOf("wordcount"))) {
HTableDescriptor hTableDescriptor=
new HTableDescriptor(TableName.valueOf("wordcount"));
HColumnDescriptor hColumnDescriptor=
new HColumnDescriptor("result");
hTableDescriptor.addFamily(hColumnDescriptor);
admin.createTable(hTableDescriptor);
}else {
admin.disableTable(TableName.valueOf("wordcount"));
admin.truncateTable(TableName.valueOf("wordcount"), true);
}
if(admin!=null) admin.close();
System.setProperty("HADOOP_USER_NAME","yui");
Configuration conf = new Configuration();
Path outpath = new Path(OUTPUT);
FileSystem fileSystem = FileSystem.get(new URI(OUTPUT), conf);
if (fileSystem.exists(outpath))
fileSystem.delete(outpath, true);
Job job = Job.getInstance(conf, "hbaseTest");
FileInputFormat.setInputPaths(job, INPUT);
FileOutputFormat.setOutputPath(job, outpath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.waitForCompletion(true);
}
}
|
八、HBase概述(伸缩性、列存储、NOSQL)、结构(列簇)、服务(三个H开头的进程)(简答、选择、判断)
1.HBase的概念,列存储优点,服务,伸缩性
(1)概念:
Hbase是bigtable的开源山寨版本。建立的HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于NoSQL和RDBMS之间,仅能通过主键(row key)和主键 的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。
主要用来存储非结构化和半结构化的松散数据。
(2)列存储优缺点:
|
行式存储 |
列式存储 |
| 优点 |
Ø 数据被保存在一起
Ø INSERT/UPDATE容易 |
Ø 查询时只有涉及到的列会被读取
Ø 投影(projection)很高效
Ø 任何列都能作为索引 |
| 缺点 |
Ø 选择(Selection)时即使只涉及某几列,所有数据也都会被读取 |
Ø 选择完成时,被选择的列要重新组装
Ø INSERT/UPDATE比较麻烦 |
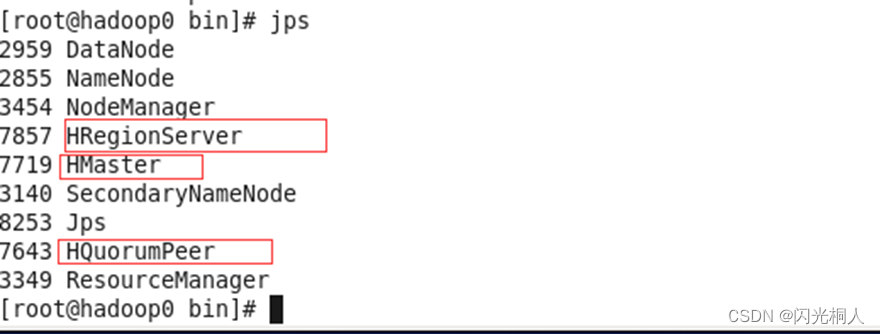
(3)服务
三个HBase的进程
(4)伸缩性
关系数据库很难实现横向扩展,纵向扩展的空间也比较有限。相反,HBase和BigTable这些分布式数据库就是为了实现灵活的水平扩展而开发的,能够轻易地通过在集群中增加或者减少硬件数量来实现性能的伸缩
2.NoSQL的概念
NoSQL 就是“Not Only SQL”缩写,泛指用来解决大数据相关问题而创建的数据库技术
NoSQL技术不会完全替代关系型数据库
常见的nosql数据库有:mongoDB,redis,Flare,CouchDB,Cassandra等等
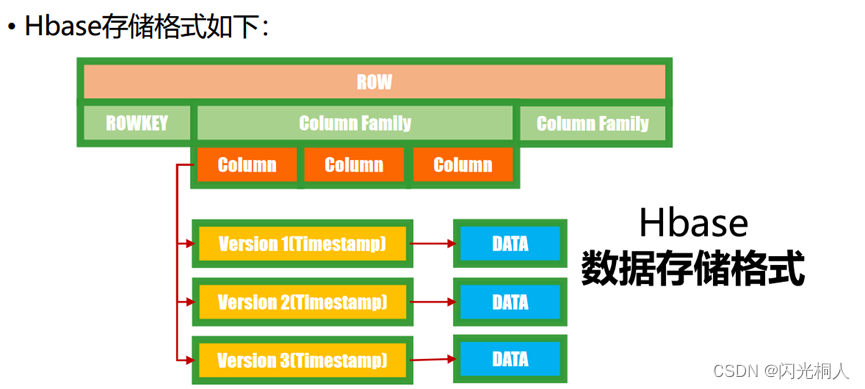
3.怎么存数据的,row-id,cf,qual,value
以列族为文件来存储数据,有多少个列族就有多少个文件,以Hfile压缩存储到HDFS
在存储数据前会根据rowKey进行数据排序,而查询数据时,是根据rowKey+列族|字段去查询数据的,因此在Hbase中,对于rowKey如何定义很重要,好的rowKey设计,能够大大提高数据的查询效率
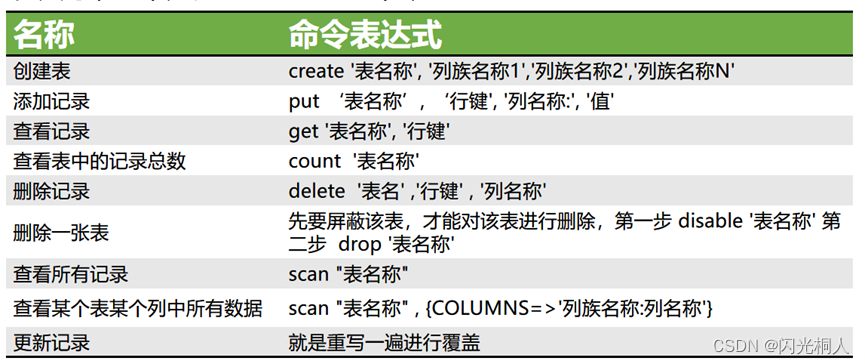
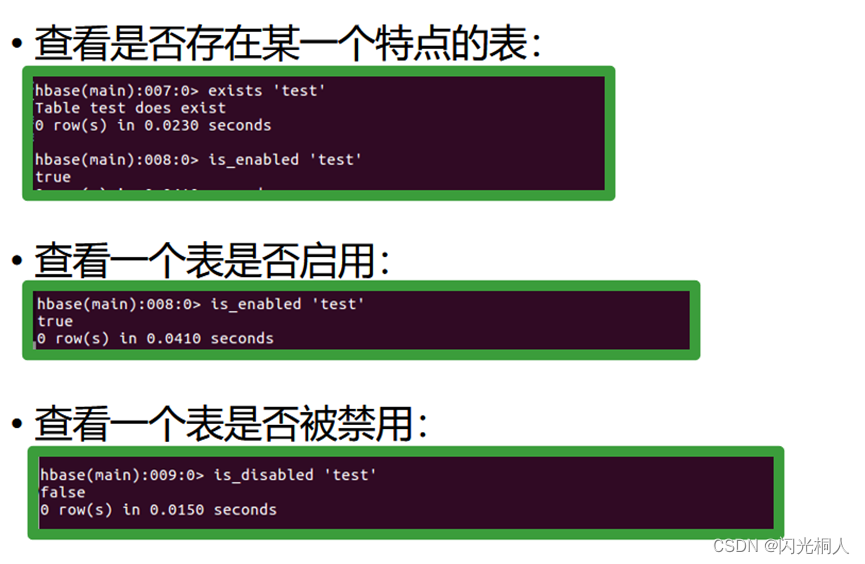
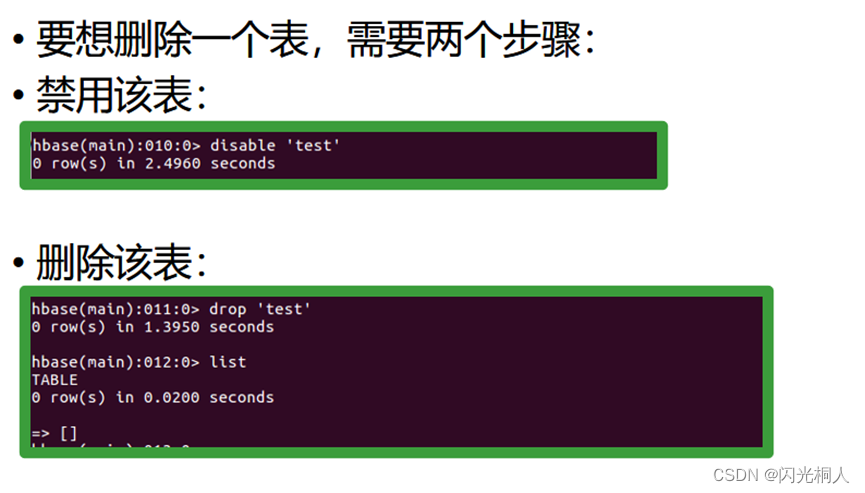
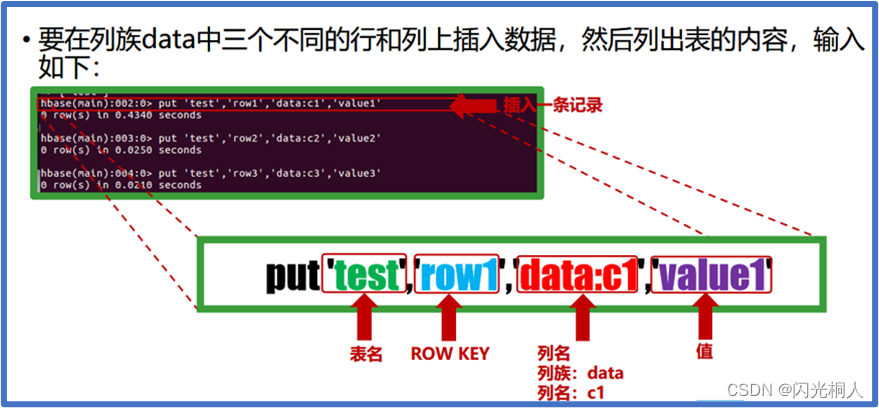
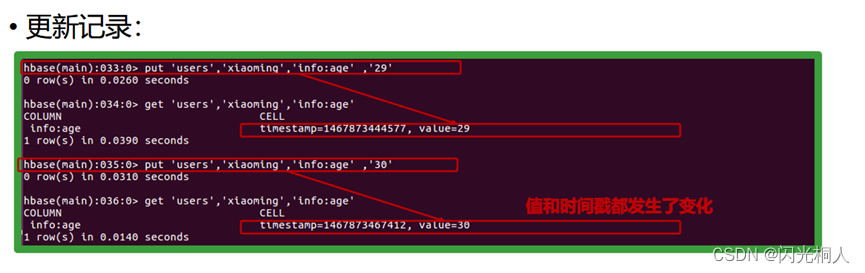
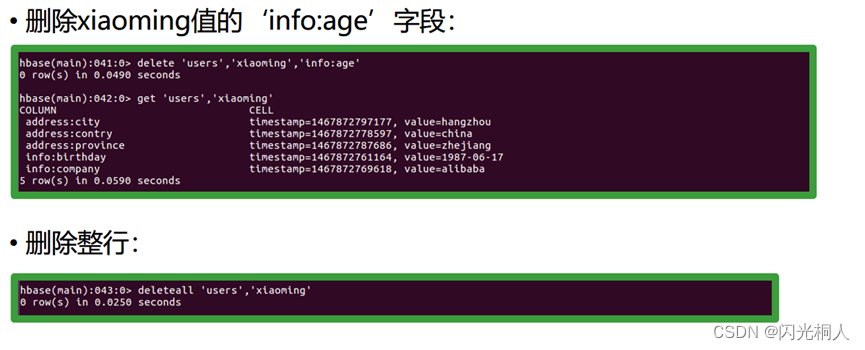
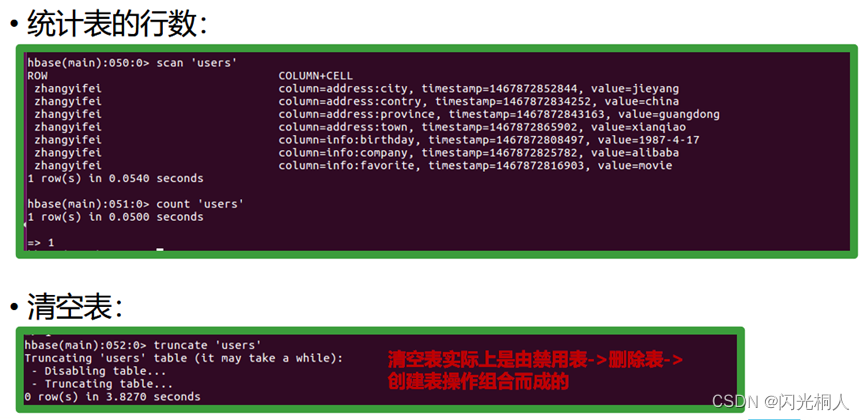
4.hbase shell常用命令