闪光桐人の实习日记(2023年2月13-17日)
本文最后更新于 2024年11月7日 下午
2023年2月17日 SpringBoot集成Redis
redis存储结构介绍
存储结构
特点
- 高速读写
- 丰富的数据类型
- 原子性(单线程读写)
- 内存共享
数据结构
高速读写快的原因
- 数组(HashTable):数组的时间复杂度是O(1),查询效率很高
- KV结构:主结构数组存的是key的Hash值,类似于HashMap
- Hash:redis对数组进行Hash计算,就是对数组的长度取余,最后将元素存到指定位置(Hash块)
- 链表法:解决Hash冲突
- 高频读取:redis通过头插法,使数据能更快地被找到
- 内存型数据库:redis所有数据都存在内存中,这也是其速度远超其他数据库的原因之一
基础数据对象介绍
最基础单元数据结构SDS
1 | |
SDS的内存分配与释放
内存分配的规则
当数据发生修改时就需要给字符串分配一些新的空间,我们来看下内存的分配规则。
初始的alloc的值和数据的实际长度大小是一样的,当数据发生修改的时候,比如追加字符,这时候有三种情况:
alloc空间足够,不作操作;
alloc空间不足够,数据量小于1M,分配2倍数据大小的空间,此时空间大小是len+2*数据大小;
数据量大于1M,再分配1M空间,此时空间大小是len+1M;
SDS扩容的时候,需求越大加得越多,扩容操作开销较大,因此redis选择多扩容一些,虽然会有部分浪费,但是减少了扩容操作次数,优化了性能。
redis检测到一块数据不常用的时候会释放掉
架构模型介绍
单线程模型
文件时间处理器的结构:
- 多个socket监听
- IO多路复用程序
- 文件事件分派器
- 事件处理器
持久化
物理性地把数据记录下来的过程就叫持久化
redis的基础持久化包含两种模式:
RDB模式
记录某一时刻的数据快照到磁盘上
特点:采用二进制+数据压缩,文件体积小,数据恢复速度快
缺点:部分情况下会丢失一小部分数据(数据快照不是最新情况)
场景:业务对数据丢失不敏感(或者对于redis数据丢失不敏感,数据可从别的数据库恢复等)
AOF模式
每一次写操作都记录到磁盘(例如:比赛的文字直播)
特点:记录的是每次写命令,数据完整
缺点:运行时间越长,恢复文件越大,恢复速度越慢
场景:业务对数据完整性要求比较高
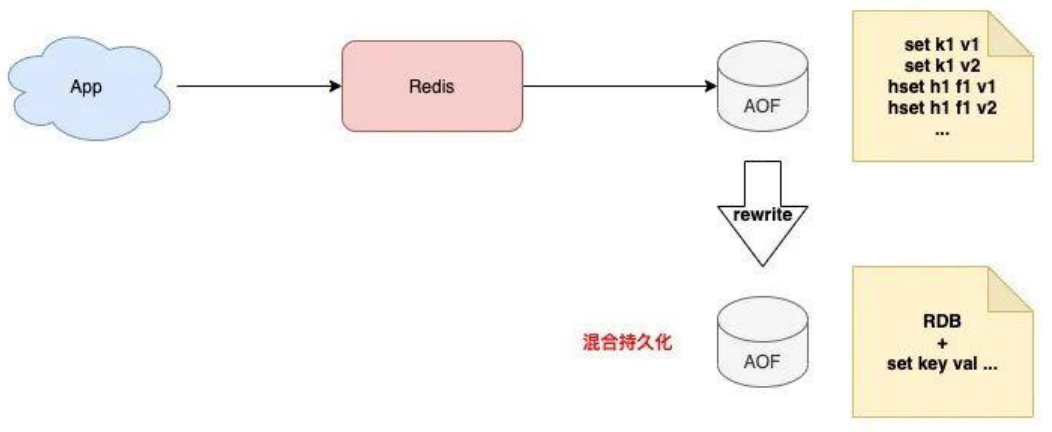
混合模式
redis在4.0后引入了混合模式:
AOF模式日志写入钱,redis先以RDB模式在AOF文件中写入一个数据快照,再把这期间产生的每一个写命令,追加到AOF文件中。而RDB是二进制压缩写入的,这样AOF的总体文件体积就变得更小了。
主从复制&哨兵模式
集群
一台服务器内存不够,就可以通过集群模式进行扩展,让redis的大脑变得更大
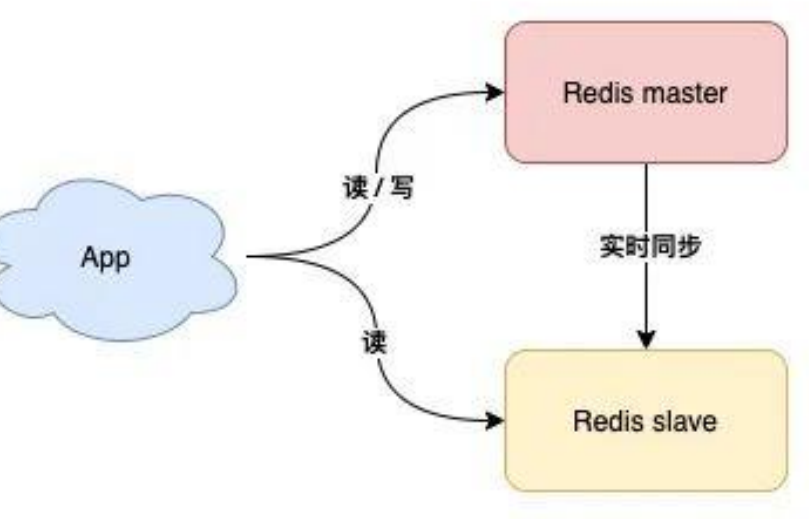
主从复制模式
主从模式需要部署多个redis实例
主节点进行实时读写
从节点实时同步主节点的数据
采用主从复制的方案
优点:
- 缩短不可用时间:主节点宕机,我们可以手动把从节点提升为主节点继续提供服务
- 提升读性能:让从节点分担一部分读请求,提升应用的整体性能(轮询分担)
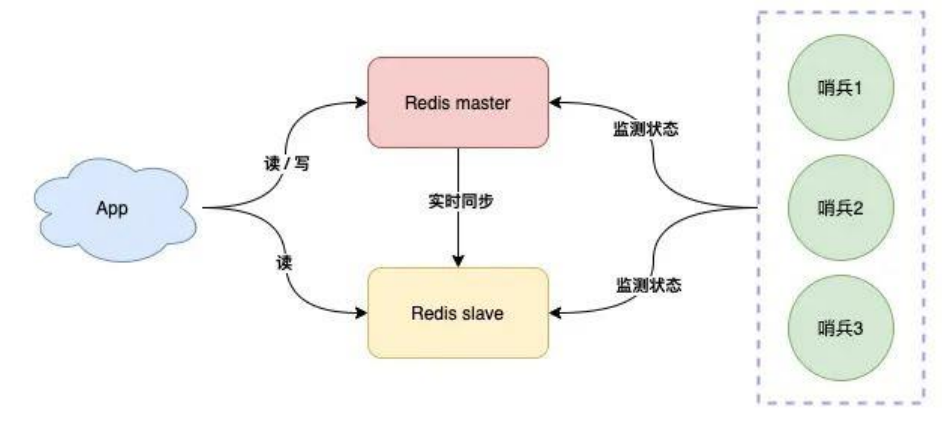
哨兵模式
哨兵模式就是实时监测主节点的健康状态,发现某个主节点出问题,主动进行切换
- 哨兵每个一段时间询问主节点是否正常
- 主节点回复了表示状态正常,回复超时表示异常
- 哨兵发现异常,发起主从切换
- 但是单个哨兵可能会因为网络异常等原因导致误识别主节点异常,可通过部署多个哨兵解决
应用场景介绍
登录验证
用户登录
用户信息存入redis并设置过期时间
key存用户id,value为用户基本信息
用户访问限制
拦截器根据url拦截,仅放行登录请求
拦截器方法根据参数userid去redis查询当前用户是否登录成功且在有效期内,也可以验证该用户是否有访问这个url的权限
热点数据查询
用户查询过去7天的数据->查询数据库
每天凌晨预先将过去7天数据存入redis->用户查询过去7天的数据->查询redis
减轻因热点数据产生的数据库负担
简单的队列
redis的单线程特性可以避免并发问题,在数据量不大的情况下可以用redis的list做简单的队列,使用lpush、rpop满足先进先出的需求
生产者生产任务->redis的list对象,lpush任务实体
消费者消费需求->redis的list对象,rpop任务实体->消费者消费任务
具体案例:
计数
单线程特性
最新列表
用队列,比如医院排队叫号、新闻时事热搜
分布式锁
Redisson分布式锁,redis的锁共享给其他业务
Redisson获取锁->业务处理->Redisson释放锁
排行榜
用zset实现自动排序(数据量不大的时候)
Springboot集成redis
这部分别的博文说得很详细了,也较少涉及底层知识,就不写了
引入redis的maven依赖
添加redis配置
添加redis配置类
封装redis工具类
小结
redis的优势
传统java项目
内存封闭:jvm托管内存数据,只能访问自己程序的内容
共享难度大:多个程序见数据交互只能通过数据库、接口或本地文件
内存数据盲盒:只能通过输出日志看内存数据,排错困难
集成redis
内存共享:通过redis共享内存数据,如配置信息、唯一id计数器
单线程:redis数据操作是单线程原子性的,在并发编程的情况下可降低代码难度,提高便携性
访问高速:redis是内存数据库,数据访问速度非常快
内存数据明盒:通过redis客户端可以实时查看内存中的数据
2023年2月16日 SpringBoot集成MybatisPlus
简介
对象关系映射(ORM)
将数据对象抽象,符合面向对象开发
常见的ORM框架:
SSH的H->Hibernate:
根据对象定义有框架生成SQL语句,属于全自动的ORM
SSM->Mybatis:
框架根据对象定义与映射配置生成最终执行的SQL语句,属于半自动的ORM
对比
Mybatis
- 持久层框架
- 自定义SQL
- 存储过程
- 高级映射
- 操作便捷
MyBatisPlus
- 只增强不修改
无侵入;损耗小;自动生成代码 - 多功能插件
分页插件;性能分析插件;全局拦截插件 - 少SQL开发
- 提高效率、强大的CRUD
提供通用的Mapper、service;ActiveRecord模式;支持Lambda表达式;主键自动生成
使用方式
引入依赖->配置文件->启动扫描
功能特点
自动注入SQL:
通用mapper
继承BaseMapper接口即可实现增删改查的基本操作
增:新增
删:自定义条件删除、主键删除
改:自定义条件修改、主键修改
查:主键查询、自定义查询条件、分页查询、统计记录数
通用service
在Mapper基础上进一步封装
增:新增、批量新增(事务)、新增或修改
删:自定义条件删除、主键删除、主键批量删除(事务)
改:自定义条件修改、主键修改、批量修改(事务)
查:主键查询、自定义查询条件、分页查询、统计记录数
ActiveRecord模式
只需在实体类继承Model类,即可实现增删改查的基本操作
注意:需要项目中已注入对应实体的BaseMapper
1 | |
Lambda表达式
正常赋值:
1 | |
Lambda表达式:
1 | |
分页
支持多种数据库
全局通用方法
Write Once, Use Anywhere
实现MetaObjectHandler接口:
- insertFill 新增时填充
- updateFill 修改时填充
典型用法
7种典型用法:
- 常用注解
- 主键填充
- 条件构造器
- 分页
- 事务
- 逻辑删除
- 乐观锁
常用注解
@TableName
@TableId
@TableFiled
主键填充
@TableId属性
value:主键字段名
type:指定转类型
- IdType.AUTO 数据库ID自增
- IdType.NONE 无状态,不自动填充
- IdType.INPUT 不自动填充
- IdType.ASSIGN_ID 自动填充数值类型主键
- IdType.ASSIGN_UUID 自动填充字符串类型主键
条件构造器
类
抽象类:AbstractWrapper
实现类:QueryWrapper、LambdaQueryWrapper、UpdateWrapper、LambdaUpdateWrapper
用于生成sql的where条件
用法
eq、ne、gt、ge、lt、le、between、like、in、groupBy、orderByAsc、orderByDesc等
分页
基本要素
- 当前页
- 每页记录量
- 总页数
- 总记录数
使用方法
配置MybatisPlus
设置数据库类型->设置单页分页条数限制->溢出总页数后是否进行处理
Page对象
事务
特性:ACID(原子性、一致性、隔离性、持久性)
@Transactional
逻辑删除
逻辑是思维的规律和规则
区别
物理删除(真删)
- 将数据从表中删除
- 执行delete语句
逻辑删除(假删)
- 将数据改为删除状态
- 执行update语句
逻辑删除的处理方式:
查询:追加where条件过滤掉已删除数据
更新:追加where条件防止更新到已删除数据
删除:编舞更新数据状态
实现步骤:
添加字段
添加配置
添加注解
乐观锁
- 乐观锁不是锁,是一种思想
- 取数后,认为数据不会被修改
- 数据如果被修改就拒绝更新
实现方式:
- 执行更新时,set version = newVer where version = oldVer
- version不对则更新失败
扩展使用
全局拦截
拦截器是全局生效的
在项目中,会出现一些对sql处理的需求,如果sql操作很多,为了简化处理,可以在sql执行的时候加入一个拦截器,并对将要执行的sql进行统一的处理。
代码生成器
Entity
Mapper
Mapper xml
Service
Controller
2023年2月15日 SpringBoot基础
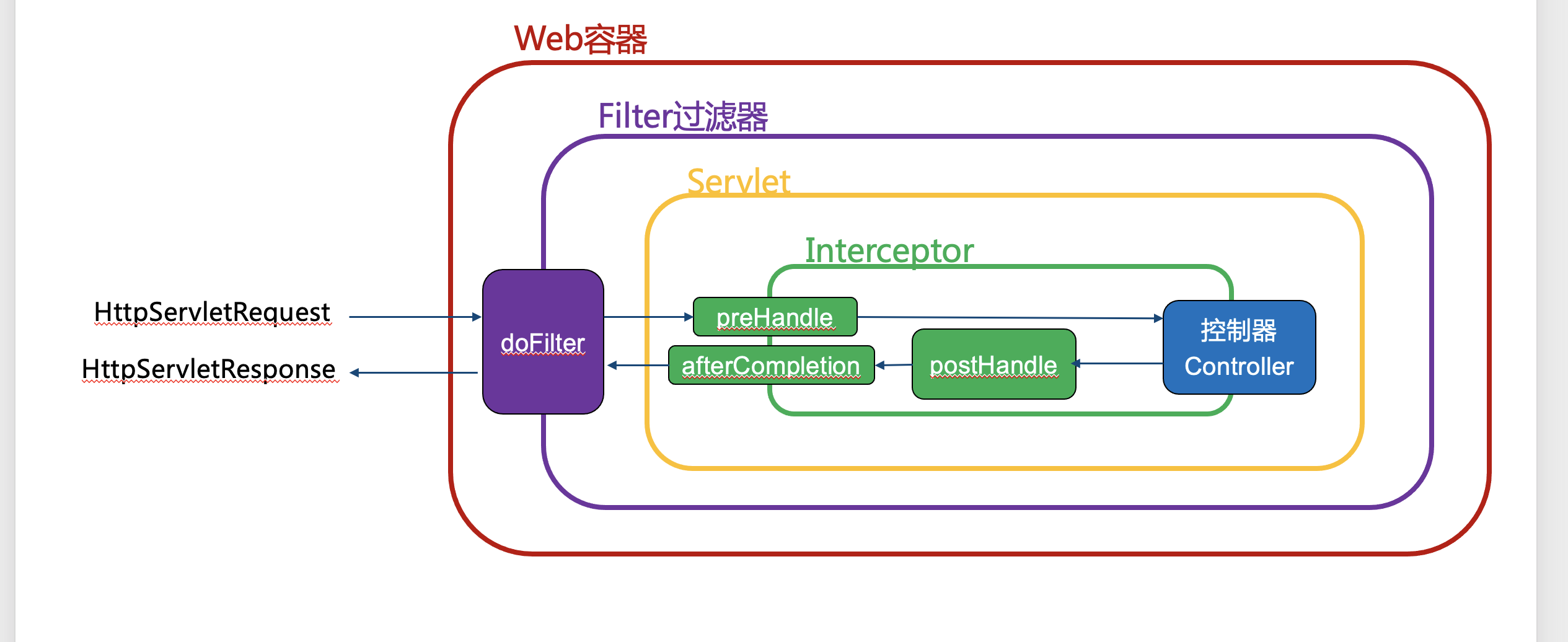
过滤器(Filter)
响应流程,请求传输过来后先进入过滤器(Filter),过滤器主要有三个部分,初始化(init),执行操作(doFilter)以及销毁(destory),最关键的就是doFilter,我们在doFilter中进行自己需要执行的操作。
1 | |
在doFilter中进行操作会需要用到它的三个参数:
服务器在得到浏览器传来的http请求后会将其封装成一个对象,这个对象就是request,因此,我们用request来获取传来的请求中包含的信息;
服务器在封装好request对象后会再封装一个response对象用于存储信息,最终将处理过的信息传递到下一层或返回浏览器;
而为了使处理好的信息可以通过过滤器继续传递,就需要执行必要操作chain.doFilter(request,response)。
HttpServletRequestWrapper
HttpServletRequest 不能对前端传来的参数进行修改,但实际应用例如过滤xss攻击,取认证token统一去除token前缀或将加密的token进行解密等需要进行请求参数的处理,此时HttpServletRequestWrapper 就应运而生了。
自己写一个包装的类,通过继承HttpServletRequestWrapper 类去重写getParameterValues,getParameter等方法,实际还是调用HttpServletRequest的相对应方法,但是可以对方法的结果进行改装。
拦截器(Interceptor)
Autowired注解报黄
使用
1 | |
写在类上可以代替@AutoWired注解,需要注意的是在注入时需要用final定义,或者使用@notnull注解,如: private final ImgService imgService。
自定义注解
- 类似于新创建一个接口文件,但为了区分,将它声明为@interface
- 自定义变量
1 | |
HandlerMethodArgumentResolver
两个方法:
- supportsParameter:作用是判断Controller层中的参数,是否满足条件,满足条件则执行resolveArgument方法,不满足则跳过。
- resolveArgument:只有在supportsParameter方法返回true的情况下才会被调用。用于处理一些业务,将返回值赋值给Controller层中的这个参数。
在拦截器中就将信息查好返回,实现对Controller层中方法参数的修改,这样controller层应用的时候只要调用一下就好了。
HandlerInterceptorAdapter
自定义拦截器,需要继承HandlerInterceptorAdapter类。
根据需求重写preHandle、postHandle、afterCompletion或afterConcurrentHandlingStarted方法。
执行顺序:
- 请求到达 DispatcherServlet
- DispatcherServlet 发送至 Interceptor ,执行 preHandle:
用户发送请求时,先执行preHandle()方法。会先按照顺序执行所有拦截器的preHandle方法,一直遇到return false为止. - 请求达到 Controller
- 请求结束后,postHandle 执行:
调用了Service并返回ModelAndView,但未进行页面渲染,可以在这里继续修改ModelAndView - 返回处理afterCompletion()方法:
已经渲染了页面,在afterCompletion中,可以根据Exception是否为null判断是否发生了异常,进行日志记录。
WebMvcConfigurer
注册拦截器,需要继承WebMvcConfigurer(WebMvcConfigurerAdapter类已被废弃)
1 | |
切面(AOP)
过滤器和拦截器的拦截都是比较粗犷的,而利用切面可以达到精准定位某一具体方法的目的。
概念
- Aspect(切面): Aspect 声明类似于 Java 中的类声明,在 Aspect 中会包含着一些
Pointcut 以及相应的 Advice。 - Joint point(连接点):表示在程序中明确定义的点,典型的包括方法调用,对类成员的访问以及异常处理程序块的执行等等,它自身还可以嵌套其它 joint point。
- Pointcut(切点):表示一组 joint point,这些 joint point 或是通过逻辑关系组合起来,或是通过通配、正则表达式等方式集中起来,它定义了相应的 Advice 将要发生的地方。
- Advice(增强):Advice 定义了在 Pointcut 里面定义的程序点具体要做的操作,它通过 before、after 和 around 来区别是在每个 joint point 之前、之后还是代替执行的代码。
- Target(目标对象):织入 Advice 的目标对象。
- Weaving(织入):将 Aspect 和其他对象连接起来, 并创建 Adviced object 的过程。
Advice 的类型
- before
- after
- round
自定义注解,然后在用到注解的地方都自动切入。
数据库
尽量做单表查询,大数据处理、数据结算除外,如果是需要快速反应的地方如页面刷新等,由程序在内存中对数据进行聚合处理,而不要用数据库来处理数据,因为数据库调优门槛较高,成本较高。相比起扩容数据库,扩容服务器性能会简单得多。
2023年2月14日
1,学习了Spring的发展历程:
JavaEE->Spring1.0(2004.3)->Spring2.0(2006.10)->Spring3.0(2009.12)->Spring4.0(2013.12)->SpringBoot(2014.6)->SpringCloud(2016.1)
SpringCloud本质上是SpringBoot的微服务解决方案,其中阿里的SpringCloud解决方案对性能的要求较高,因此在实际应用中不常用。
2,学习了Spring Boot项目的结构规范
2.1,结构:
- src/main/java:java代码;
- src/main/resources:外部的配置文件;
- src/main/application.yml:项目的工程配置文件,约定优于配置,但是此处的自定义配置会覆盖默认配置(约定);
- src/test:单元测试代码的代码文件;
- target:依赖工具打包构建生成的Jar文件所在的地址;
- pom.xml:maven构建配置。
2.2,规范:
controller只做参数校验,不参与业务;
业务由service层的具体实现类去实现,目的是为了各个service不会造成循环依赖,造成Spring启动的时候不知道先后顺序;
entity层是与数据库直接交互的,dto层的实体类才是参与前后端数据传输的,避免一个实体类要规定很多字段不用与数据库交互显得臃肿;
dao层只调用自己这一服务的组件。
一切的发展、规定、解决方案、规范都是为了“高内聚,低耦合”这个终极目标。
3,学习了依赖管理工具Maven
3.1,maven在idea中的配置和使用
idea的setting里设置maven的仓库路径,可以通过自定义maven的settings.xml文件可以更改镜像源加快下载速度;
clean、package、install的作用。
3.2,pom.xml的结构
- parent指定父模块;
- properties指定依赖版本等配置;
- dependencies管理具体依赖;
- repositories指定maven仓库源;
- pluginRepositories指定插件仓库源。
4,学习了Spring Boot启动原理
内置web服务器,且默认配置好了各项选项,有约定大于配置的特性,起步依赖简化了配置。利用反射、注解和依赖进行自动化配置,一键启动。
5,学习了前后端数据交互过程中后端的接口管理
响应的数据格式,其中现在流行的是json格式,但第三方接口如支付宝和微信用的仍是表单格式的数据,在使用的时候要注意。
Restful是一种风格,不是强制要求。
按照规范,post请求负责增添、put请求负责更新、delete请求负责删除、get请求负责查询,但仍要注意有的项目在配置之初就只允许post跟get请求,在实际开发中要多加注意。
6,学习了swagger接口文档生成
Swagger在SpringBoot中的配置是使用Docket来控制Swagger的配置;
Swagger的接口分组,相比于按照包名、路径去分组,自己自定义一个注解比较灵活;
访问地址是http://localhost:项目端口/项目名/swagger-ui.html。
2023年2月13日
1,认识了职场礼仪,学习了职场礼仪的重要性
尊重->心情愉悦->建立信任与好感->合作机遇的敲门砖
2,学习了职场礼仪中的邮件礼仪
模板管理中设置自己的名片
部门写到三级部,如果部门名太长要换一行
发送者、抄送者、密送者之间的区别
提炼出有意义的主题行
正文格式:字体统一、格式规范、内容简明;开门见山,先说结果或意图,然后是正文内容,最后致谢
附件格式:命名要清晰,正文要提醒,内容要简介